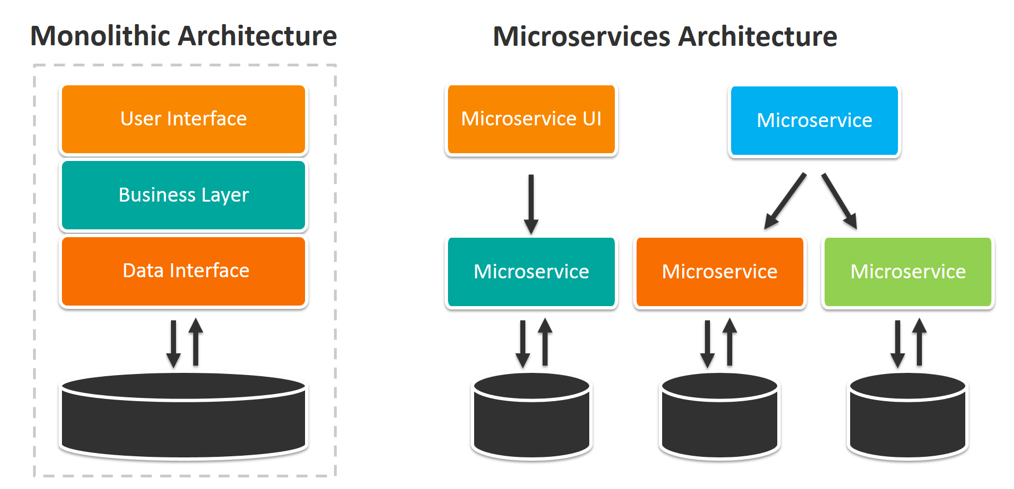
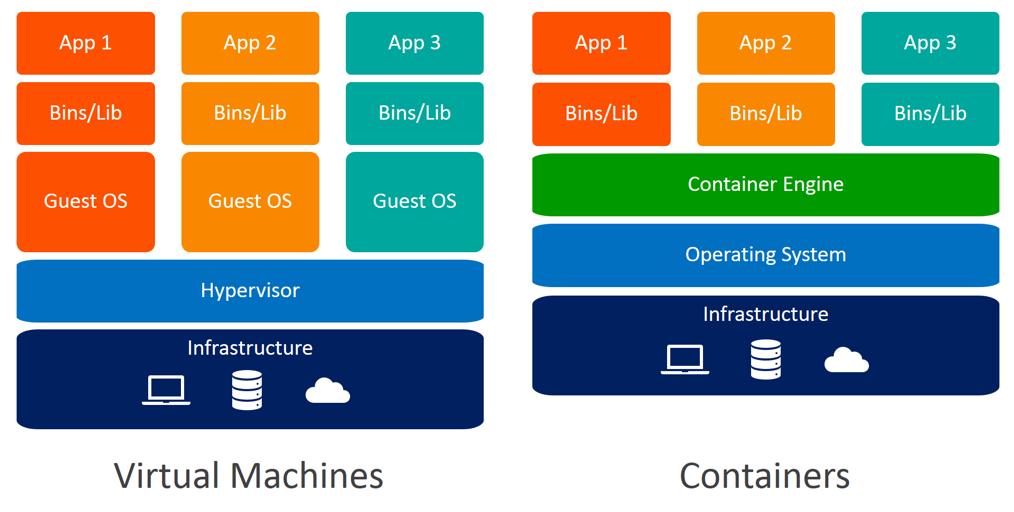
Plataformas y tecnologías cloud
Hoy en día existen muchas soluciones para alojar servicios o sistemas remotos aunque una de las más conocidas es la “nube”. En esta entrada veremos los distintos tipos de arquitecturas remotas (on-cloud).
Antes de centrarnos en las soluciones y tecnologías Cloud o remotas deberíamos de explicar tres tipos de arquitecturas posibles:
- Implementación Local (privada) — > Se basa en mantener toda la infraestructura física en una o varias localizaciones propias de una empresa u organización y que en ocasiones se puede gestionar como una “nube privada”. Emplean soluciones virtualizadas aunque se asemeja a la infraestructura de TI antigua.
- Implementación Híbrida — > Es una solución que se basa en conectar la infraestructura local o privada de una empresa con la nube. Es una solución óptima para accesos a información rápida localmente y desde cualquier parte del mundo gracias a la nube pública. Además, se pueden realizar copias de seguridad on-cloud. Su gran desventaja es la duplicación de servicios, su sincronismo y el consumo de recursos económicos, de equipos y de personal.
- Implementación en la nube — > Toda la infraestructura TI se encuentra en la nube que o bien se creó originalmente allí o se transfirió desde una solución local.
SaaS, PaaS y IaaS
Existen muchos conceptos difíciles de entender y asociados con “la nube”. Algunos son de difícil clasificación puesto que no se sabe bien cuando entran en una categoría o en otra.
Los servicios “on-cloud” pueden ser:
- Software-as-a-Service (SaaS) — > Este servicio comprende los que proporcionan una funcionalidad directa sin que el que lo despliega (o desarrolla) tenga conocimiento expreso de la plataforma o infraestructura sobre la que subyace. Ejemplos de SaaS pueden ser Gmail, Dropbox, Alojamiento web, etc. Aquí el usuario se ocupa solo del empleo de la herramienta (aunque sea con permisos de administrador como en una web o blog).
- Platform-as-a-Service (PaaS) — > En este caso los desarrolladores pueden interaccionar no solo con la funcionalidad o el servicio sino con la estructura que “soporta” ese servicio. Sin embargo el auto escalado, o las propias redes informáticas son autogestionadas por la plataforma sin que el desarrollador pueda configurarlas. Si puede, sin embargo, configurar espacio, memoria RAM, discos duros, etc. Son unos servicios óptimos para el desarrollo de aplicaciones eficientes con una gestión parcial de los recursos asociados en las plataformas. Ejemplos de esto pueden ser Google App Engine que permite desarrollar soluciones en Java o Python.
- Infraestructure-as-a-Service (IaaS) — > En este caso el desarrollador se ocupa no solo de los servicios y su desarrollo sino de su infraestructura (máquinas virtuales, auto escalado, redes, elección de hardware, sistemas operativos, etc.): ejemplo de esto puede ser AWS, Azure, Google Cloud, vCloud (VMware), etc.
En la siguiente tabla tenemos una comparación entre las más conocidas plataformas.
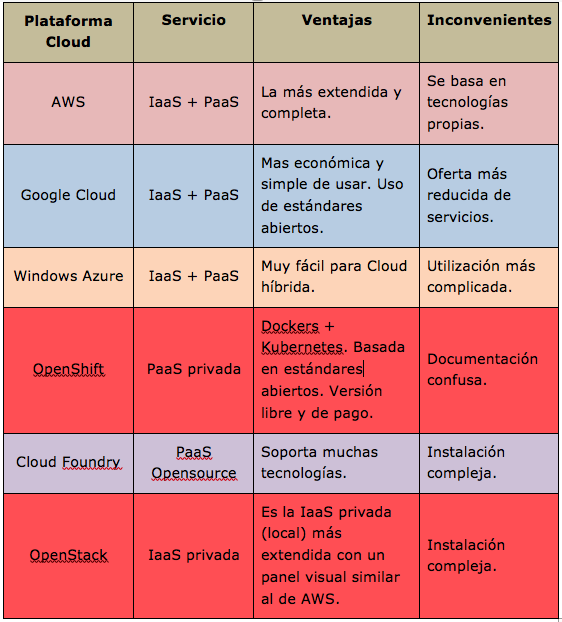
Antes de seleccionar un proveedor para trabajar con el deberíamos tener en cuenta unos conceptos asociados a los servicios on-cloud y que nos permiten poder contratar un servicio con unos requerimientos especifico o firmar una SLA (Service Level Agreement) con un proveedor especifico. Los mas importantes que debemos saber son:
- RTO — > Recovery Time Objective. Se refiere al tiempo que tardamos en recuperar esos datos al estado que estaban antes del “incidente”.
- RPO — > Recovery Point Objective. Se refiere a la cantidad de datos que podemos recuperar. Es decir, desde cuando podemos recuperar los datos. Por ejemplo, si tenemos un backup de las últimas 4 semanas nuestro RTO será de 4 semanas.
- IOPS — > Inputs Outputs Per Second. Se refiere al rendimiento de los discos duros o sistemas . Así IOPS nos marca la velocidad (mínima) que puede un disco duro leer datos y escribirlos .