El pantalón asesino
Esta entrada podría haber sido publicada en el bloque de “Nuestro amigo el docker” https://seguridadzero.com/nuestro-amigo-el-docker , sin embargo, al ser una entrada especifica de seguridad he preferido ubicarla aquí.
Nota: Si alguien quiere conocer mas sobre vuestros “pantalones” (Dockers J) le aconsejo que visite le bloque de “Nuestro amigo el docker”.
Slaxx es una película que trataba de unos pantalones “asesinos”. Igual que en Slaxx, nuestros “pantalones” pueden “matar” la seguridad de nuestro sistemas si no se encuentran bien securizados.

Antes de empezar a hablar de la seguridad en Dockers (o contenedores) os daré unas pequeñas “pinceladas” de cómo se crean y lanzan estos contenedores para que no os perdáis al entrar en el apartado de seguridad. Esto esta muy detallado y explicado en el bloque comentado de dockers.
Un repaso rápido
La instalación de docker (community edition) en una maquina (virtual o física) Linux (Ubuntu) se compone de las siguientes instrucciones:
| apt-get update && upgrade apt-get install docker-ce docker-ce-cli containerd.io |
Para crear imágenes podremos descargarlas ya creadas (Docker Hub) o emplear un archivo “dockerfile” o “compose”
Dockerfile
Un “dockerfile” es un archivo de texto donde se establecen una serie de comandos (similares a un pseudo Linux) que hace que el cliente docker (el docker que corre en nuestra máquina) los ejecute cuando crea una imagen. Obviamente las imágenes se basan en otras imágenes (como ya se ha explicado) como puede ser una imagen de Ubuntu o Phyton (como en nuestro ejemplo). Estas imágenes “base” tienen las funcionalidades necesarias para luego “añadirle” otras en nuestra imagen “customizada”.
Un ejemplo para crear una imagen a través de un “dockerfile” muy simple con base una maquina Ubuntu 16.04 sería el siguiente archivo:
| FROM ubuntu:16.04 RUN apt-get update && upgrade RUN apt-get install -y apache2 RUN echo “Bienvenido a seguridadzero!!!!” > /var/www/html/index.html EXPOSE 80 |
La explicación de este archivo es casi obvia, creamos una imagen de Ubuntu 16.04 al que le forzamos a actualizarse y a que se instale apache (“-y” significa que a todas las preguntas diga SI), que en la página web muestre un mensaje de bienvenida (siempre recogida en index.html) y que estará disponible (se expondrá) en el puerto 80.
Así, para construir nuestra imagen (obviamente la máquina de Ubuntu se obtiene de Docker Hub) ejecutamos el siguiente comando docker build -t ubuntutest .
Hay que tener claro que “-t” se refiere a “tag” (para poner el nombre a la imagen) y que el “.” final es necesario para decirle que lea el “Dockerfile” para crear la imagen en el propio directorio donde estamos.
Finalmente, con el comando docker run -d -p 80:80 ubuntutest /usr/sbin/apache2ctl -D FOREGROUND lanzamos el contenedor de la imagen creada forzando a que arranque el servidor apache (en background ya que un docker necesita ejecutar en primer plano el proceso principal “Ubuntu” y en background el resto) en el puerto 80. Cuando se encuentre en ejecución nos devuelve un UUID (identificador único universal) que se corresponde al contenedor ejecutándose.
COMPOSE
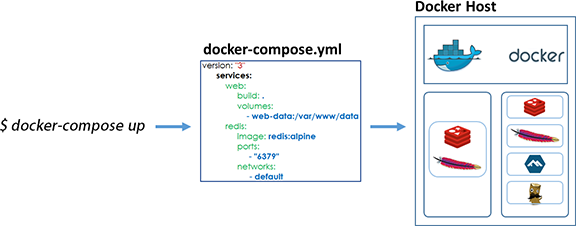
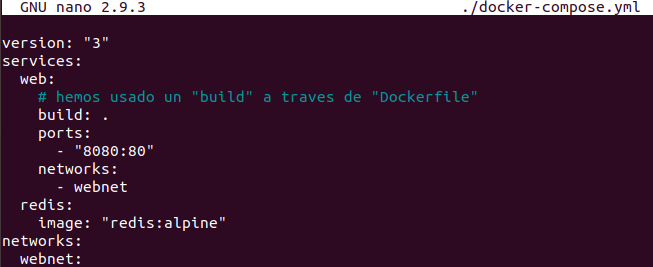
El archivo “docker-compose.yml” es un archivo que define como se ha de comportar un servicio (de varios contenedores Docker) en producción (es decir “corriendo”). Un ejemplo de archivo “compose.yml” es el siguiente:
| version: «3» services: web: #Reemplazar el usuario y el repositorio con la imagen que queramos descargar (github) image: username/repo:tag deploy: replicas: 5 resources: limits: cpus: «0.1» memory: 50M restart_policy: condition: on-failure ports: – «4000:80» networks: – webnet networks: webnet: |
El ejemplo anterior genera 5 réplicas de un container (servicio) asignándole 0,1 de CPU y 50 Mb de RAM a cada réplica. Lo más interesante es la respuesta en caso de fallo (condition: on-failure) que reinicia el contenedor que falle. Además, se mapea el puerto 4000 al 80 balanceando la carga en una red que se ha llamado “webnet” (podríamos haberla llamado de cualquier otra manera) esta red permite gestionar la carga entre los contenedores. El balanceo puede ser “leastconn”(el que tenga menos conexiones) o “roundrobin” (por defecto).
Para usar el archivo “docker-compose.yml” lo podemos hacer de 2 maneras:
- Como un archivo que crea unos contenedores como servicios: En este caso se ejecuta con las siguientes instrucciones:
- docker-compose up — > Da instrucciones a Docker para crear el contendor, y ejecutarlo según docker-compose.yml (busca ese archivo por defecto).
- docker-compose down — > Apaga todos los servicios que levantó con docker-compose up.
- docker-compose ps — > Permite ver los contenedores funcionando.
- docker-compose exec — > Permite ejecutar un comando a uno de los servicios levantados de Docker-compose.
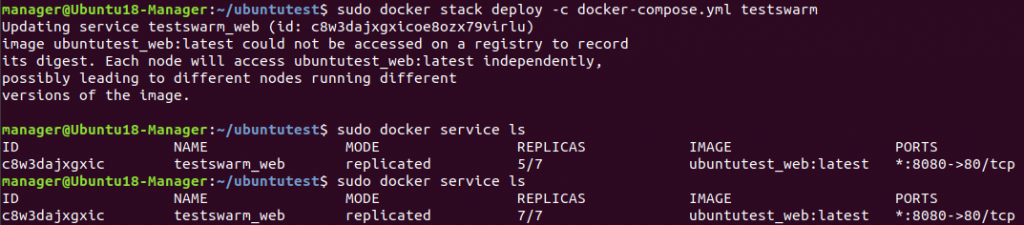
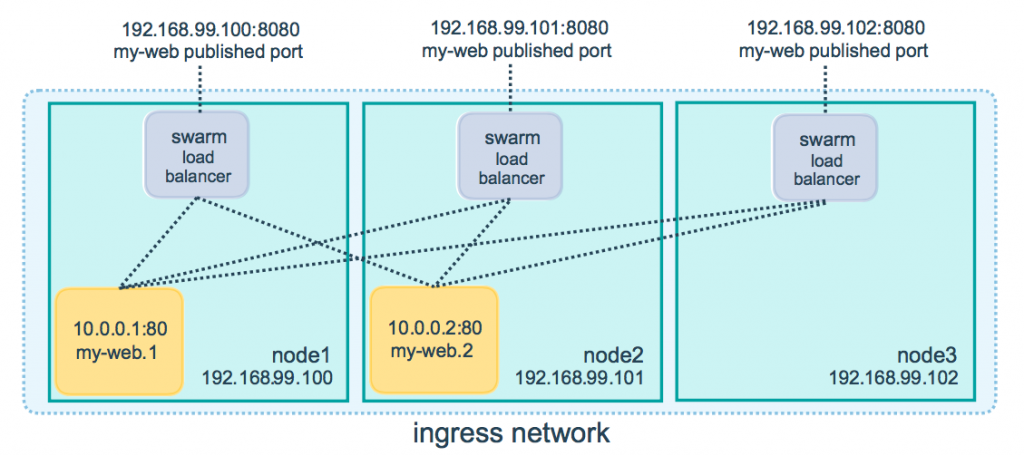
- Como archivo para levantar un stack (Swarm). Un Swarm es una ”colmena” de hosts donde se ejecutan contenedores con una sola URL para todos (balanceo de carga).
La seguridad en Dockers
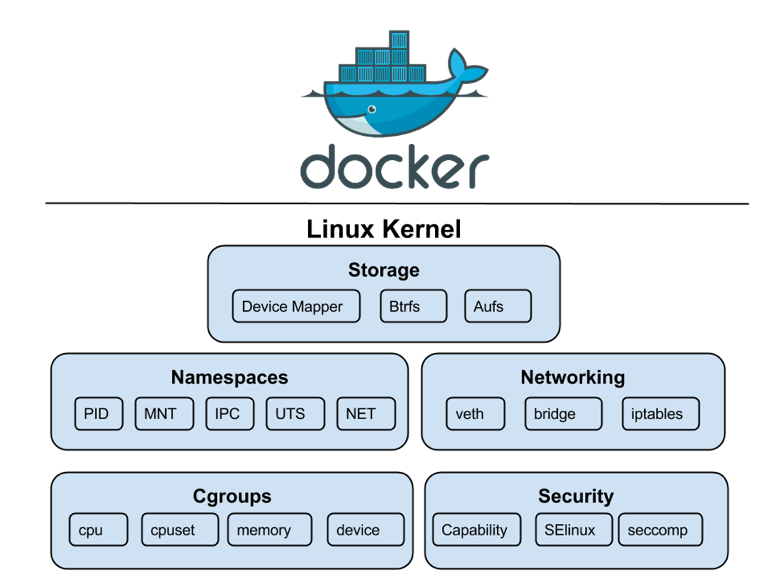
Hasta ahora no se ha hablado específicamente de la seguridad que nos brindan los contenedores y que se consigue (a parte de su aislamiento como cualquier otra maquina virtual) a través de las siguientes funcionalidades que residen en el kernel de Linux y que podemos aprovecharnos al lanzar contenedores:
- Namespaces — > Los namespaces permitirán espacios aislados para los procesos que contienen, lo que protege el sistema de acciones que suceden en el interior de la sandbox creada. Es decir que podremos permitir a un usuario ejecutarse en el “interior” del contenedor como “root” pero como un usuario sin privilegios especiales fuera de ese contenedor.
- Cgroups (Control Groups) — > Los control groups, permiten gestionar los recursos que se atribuyen a ciertos procesos, siendo posible de este modo asignar límites cuantitativos de CPU, memoria, acceso a disco, etc. Esto es muy útil para asegurar que el sistema no pueda ver comprometidos sus recursos. Es decir que asignamos unos recursos específicos dentro de un contenedor específico.
- Usuario con privilegios para lanzar el demonio Docker — > El Docker daemon debe ser lanzado por un usuario con privilegios “root” o un usuario dentro del grupo “docker” que no sea root.
- Capabilities — > Las capabilities son propias de un kernel Linux en el que permite ciertas acciones en su entorno, pero no fuera de él. Es decir permite ejecutarse las acciones específicas dentro del kernel del host anfitrión pero podemos limitar esas capacidades para que solo se ejecuten en un contenedor pero NO en el kernel del host anfitrión.
Usuario con privilegios para lanzar el demonio Docker
En los ejemplos vistos hasta ahora no se ha puesto de manifiesto que la ejecución de los comandos de docker necesitan permisos de root (o sudo). Lo ideal es crear un usuario específico para poder lanzar y crear nuestros contenedores. Para crear un usuario docker específico para la ejecución de sus comandos se puede realizar lo siguiente:
- Crear o usar un usuario con privilegios de “root”.
- Crear (si no existe ya) el grupo docker — > sudo groupadd docker
- Añadir el usuario anterior (estamos logados en el) al grupo docker — > sudo usermod -aG docker $USER (La variable $USER es el usuario que estamos empleando en la consola).
- Reboot (Reiniciar el equipo).
Capabilities
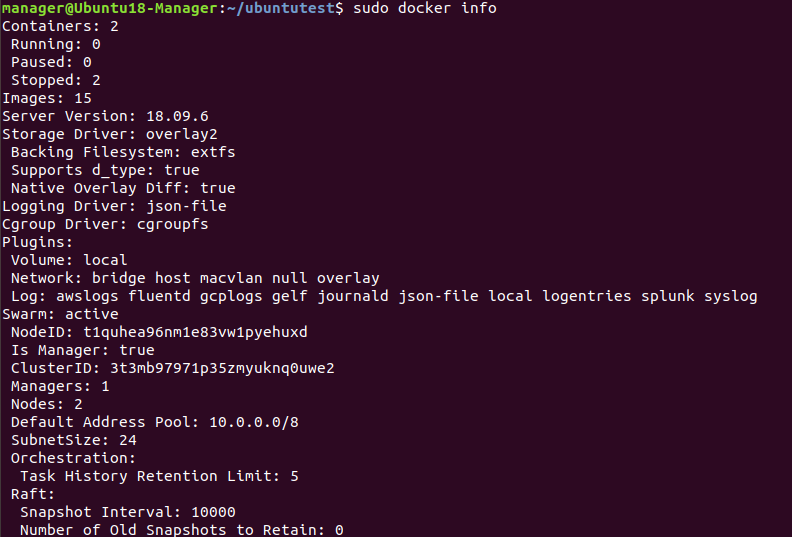
Podemos ver las capacidades de nuestros usuarios con el comando pscap | head -10 con esa consulta en nuestro host vemos los siguiente:
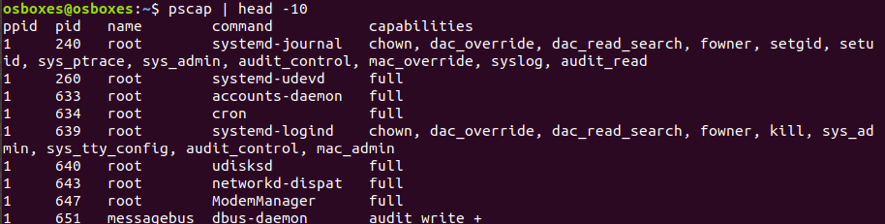
Ahí vemos que el usuario “root” tiene diferentes capacidades como chown, syslog, etc… según sea el proceso que este ejecutándose (PID).
¿Cómo podemos “limitar” esas capacidades al lanzar un contenedor?
Podremos a través del comando de la imagen siguiente en el cual solo queremos que se ejecuten las capacidades “setuid” y “setgid” en el kernel del host anfitrión.

Como vemos con “–cap-drop=all” eliminamos todas las capacidades y las añadimos con “–cap-add=”.
Una forma útil de emplear esta restricción de capacidades es la de usar “atomic” (herramienta) para ejecutar imágenes que tengan en su creación (en el Dockerfile) unas etiquetes (Labels) que eliminen o añadan capacidades.
Cgroups
Los recursos (CPU, memoria, redes, disk i/o, etc.) empleados en los contenedores pueden dejar bloqueado un host sino se limitan adecuadamente. Como ya sabemos, la limitación de recursos es una medida de seguridad para que los contenedores no consuman todos los recursos de un host y puedan bloquear al resto de contenedores.
Existen varias maneras de limitar los recursos:
- En la propia ejecución del contenedor — > A partir de docker engine 1.13 se puede lanzar un contenedor con $docker run -it –cpus=».5″ ubuntu /bin/bash en el que se limita ese contenedor al consumo de 0,5 del recurso de la CPU (esto mismo se puede hacer con la memoria)
- En el archivo docker-compose.yml — > Como ya hemos visto, existen restricciones del tipo:
limits:
cpus: ‘0.50’
memory: 50M
reservations:
cpus: ‘0.25’
memory: 20M
Donde se limita un “techo” de 0,5 en CPU y de 50 MB en memoria con una reserva de (al menos) 0,25 y 20 MB respectivamente.
- A través de cgroups — > Un cgroup es una característica o servicio proporcionado por el kernel de Linux. Esta caracteristica permite crear un grupo de control (control group o cgroup) con unas limitaciones de recursos para luego aplicar ese cgroup al contenedor. Esta forma es un poco más laboriosa que las dos anteriores con lo que se aconseja emplear las dos anteriores.
Namespaces
Existen 6 tipos básicos de namespaces relacionados con distintos aspectos del sistema:
- NETWORK namespace — > Aislamiento de red. Así, cada namespace de red tendrá sus propios interfaces de red, direcciones de red, tablas de enrutamiento, puertos de red, etc.
- PID namespace — > Aísla el espacio de identificadores de proceso. Un contenedor tendrá su propia jerarquía de procesos y su proceso padre o init (PID 1).
- UTS namespace — > Aísla el dominio y hostname, permitiendo a un contenedor poseer su propio dominio de nombres.
- MOUNT namespace — > Aísla los puntos de montaje de los sistemas de ficheros que puede ver un grupo de procesos. Este namespace fue el punto de partida que nació con chroot.
- USER namespace — > Aísla identificadores de usuarios y grupos. Así dentro un contenedor es posible tener un usuario con ID 0 (root) que se corresponda con un ID de usuario cualquiera en el host.
- IPC namespace — > Aísla la intercomunicación entre procesos dentro del espacio.
La forma más efectiva de prevenir ataques de escalamiento de privilegios desde un contenedor es configurar las aplicaciones de su contenedor para que se ejecuten como usuarios sin privilegios, es decir aplicar un “USER namespace”. Así, para los contenedores cuyos procesos deben ejecutarse como usuario “root” dentro del contenedor se puede “mapear” a este usuario con un usuario con menos privilegios en el host anfitrión de Docker. Al usuario asignado se le asigna un rango de UID (0- 65536) que no tiene privilegios en la máquina host (tened en cuenta que un UID = 0 es el de “root”).
Para realizar lo anterior podemos crear un un archivo llamado “daemon.json” y que se emplea en el arranca del contenedor. En su arranque se remapea el usuario para docker de tal manera que dentro del contenedor se comporta como “root” pero fuera tendar un UID de menor privilegio.
En la siguiente imagen el usuario de dentro del contenedor NO puede modificar un archivo que necesita privilegios de root fuera del contenedor (incluso aunque acceda a él).
Y eso es todo, espero que os haya resultado interesante esta entrada de seguridad aplicada a contenedores.
geropa!!!!